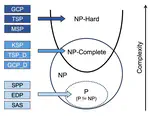
NPHardEval serves as a comprehensive benchmark for assessing the reasoning abilities of large language models (LLMs) through the lens of computational complexity classes. This repository contains datasets, data generation scripts, and experimental procedures designed to evaluate LLMs in various reasoning tasks.
The benchmark offers several advantages compared with current benchmarks:
- Data construction grounded in the established computational complexity hierarchy
- Automatic checking mechanisms
- Automatic generation of datapoints
- Complete focus on reasoning while exclude numerical computation