Biography
Haoyang Ling is a second-year master’s student at the University of Michigan, pursuing a degree in Information Science with a focus on Big Data Analytics. His interests include artificial intelligence, natural language processing, information retrieval, and programmable matter. With a strong foundation in both computer science and data science, he has worked on many data science-related course projects that have real-life applications with an eagerness to apply knowledge and expertise to make meaningful contributions to this field.
- Artificial Intelligence and Information Retrieval
- Machine Learning and Statistics
- Big Data Analytics
MSc in Information Science (GPA 4.0/4.0), 2024
University of Michigan
BSc in Electrical and Computer Engineering (GPA 3.92/4.0), 2023
Shanghai Jiao Tong University
Projects
Simple Summarizer
It contains a React-based summarizer built with ChatGPT whose primary purpose of the application is to generate a summary of paragraphs with highlighting of the relevant keywords. It aims to facilitate the comprehension of the original text and to enhance user trust in the generated summary. I also make efforts in protecting the personally identifiable information (PII) with Presidio.
- Tools: Docker, OpenAI, Presidio, ReactJS, Flask (gunicorn + gevent), Celery (Redis + MongoDB), Nginx, JMeter

- Discriminated statistical information of machine-generated text to propose an explainable classifier, achieving comparable predictability to BERT-based models.
- Performed a thorough analysis of data augmentations on response length, identifying that truncated sentences can decrease the model performance by around 5%


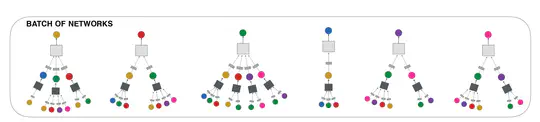
Augmented graph data with random masking and self-attention after comparative analyses
to enhance the model’s robustness, surpassing baseline models in 5 out of 9 datasets.
This is a project for music recommendations with Spark.
- Accelerated parallel breadth-first search with Spark 10x faster than that with MapReduce in the self-deployed cluster after compressing the dataset with a 2% ratio by Apache Avro.
- Employed the PageRank algorithm within ego-nets to generate divers.

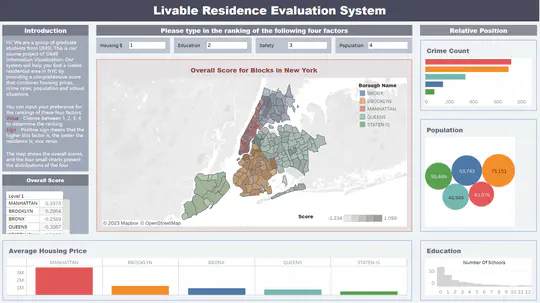
This project involves working with a dataset from the Cook County Assessor’s Office in Illinois, which contains over 500,000 records describing houses sold in the area in recent years. The dataset is split into training and test sets.
In Part 1, Exploratory Data Analysis (EDA) ais performed. In Part 2, the focus is on advanced prediction with machine learning. The criterion for evaluation is L2 loss, and the baseline model is ridge regression.

Experience
Responsibilities include:
- SI 671 Data Mining Discussion
Responsibilities include:
- Deploying the McityGPT with LangChain to introduce Mcity to newcomers with useful information from the website.
- Understanding the basics of importance sampling and natural driving enviornment.
- Researching on the autonomous vehicle safety test with Traci sumo by modelling the traffic accidents in the natural adversarial driving environment (NADE).
- Calibrating the distribution of traffic accidents with experiments in Great Lakes.
Responsibilities include:
- Understood the basics of GNN including GCN and GAT and the usage of PyTorch and PyTorch Geometric.
- Compared GNN with Computer Vision and Natural Language Processing in data augmentation and searched for similarities.
- Investigated contrastive learning methods in graph representation learning and fine-tuned models with random masking and attention masking.
Responsibilities include:
- Taught Physics and Circuit theory by providing RC and OH for around 150 students.
- Scored homeworks and exams and prepared exam questions.
- Obtained praise as a teaching assistant.
Recent Work
Contact
My research interests include artificial intelligence, information retrieval, and programmable matter. If you are interested in working together or have any questions, please feel free to contact me using the information below. I would love to hear about any opportunities that may be a good fit for my skills and experience.